导航
安装教程导航
- Mamba 及 Vim 安装问题参看本人博客:Mamba 环境安装踩坑问题汇总及解决方法(初版)
- Linux 下Mamba 及 Vim 安装问题参看本人博客:Mamba 环境安装踩坑问题汇总及解决方法(重置版)
- Windows 下 Mamba 的安装参看本人博客:Window 下Mamba 环境安装踩坑问题汇总及解决方法 (无需绕过selective_scan_cuda)
- Linux 下 Vim 安装问题参看本人博客:Linux 下 Vim 环境安装踩坑问题汇总及解决方法(重置版)
- Windows 下 Vim 安装问题参看本人博客:Window 下 Vim 环境安装踩坑问题汇总及解决方法
- Linux 下Vmamba 安装教程参看本人博客:Vmamba 安装教程(无需更改base环境中的cuda版本)
- Windows 下 VMamba的安装参看本人博客:Windows 下 VMamba 安装教程(无需更改base环境中的cuda版本且可加速)
- Windows下 Mamba2及高版本 causal_conv1d 安装参考本人博客:Windows 下Mamba2 环境安装问题记录及解决方法(causal_conv1d=1.4.0)
- Windows 下 Mamba / Vim / Vmamba 环境安装终极版参考本人博客:Windows 下Mamba2 / Vim / Vmamba 环境安装问题记录及解决方法终极版(无需绕过triton)
安装包导航
- Mamba 安装教程博客中涉及到的全部安装包:mamba 安装包,包括Windows和Linux
- Vim 安装教程博客中涉及到的全部安装包:vim 安装包,包括Windows和Linux
- Vmamba 安装教程博客中涉及到的全部安装包:vmamba 安装包,包括Windows和Linux
- Mamba2 及 更高版本causal_conv1d Windows安装包:mamba 2 windows安装包
(安装问题 / 资源自取售后 / 论文合作想法请+vx:931744281)
目录
- 导航
- 安装教程导航
- 安装包导航
- 背景
- 安装步骤
- 1. Windows 下前期环境准备
- 2. triton-windows 环境准备
- 3. 从源码编译causal-conv1d 1.4.0 版本
- 4. 从源码编译 mamba-ssm 版本
- 5. Mamba 环境运行验证
- 6. Windows 下 Vim 的安装
- 7. Vim 环境运行验证
- 8. Windows 下 Vmamba 的安装
- 9. Vmamba 环境运行验证
- 出现的问题
- 1. 出现 `fatal error C1083: 无法打开包括文件: “nv/target”'`
背景
在笔者之前的系列博客中,例如 Windows 下Mamba2 环境安装问题记录及解决方法(causal_conv1d=1.4.0),以及 Window 下 Vim 环境安装踩坑问题汇总及解决方法 遭遇了与 triton 有关的问题,之后在本人博客 Windows 下安装 triton 教程 之后,终于实现了 mamba / vim / vmamba 在Windows下,无需更改重要代码,直接运行程序。本博客安装版本为:mamba_ssm-2.2.2 和 causal_conv1d-1.4.0。CUDA 版本为12.4。
安装步骤
1. Windows 下前期环境准备
前期环境准备,类似原来博客 “Windows 下Mamba2 环境安装问题记录及解决方法(causal_conv1d=1.4.0)” ,但是由于 triton-Windows 对 CUDA 版本的高要求,所以具体更改为:
conda create -n mamba python=3.10
conda activate mamba
# CUDA 12.4
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu124
python -c "import torch; print(torch.cuda.is_available())" # 验证torch安装
# 安装cuda
conda install nvidia/label/cuda-12.4.0::cuda-nvcc
pip install setuptools==68.2.2
conda install packaging
windows__45">2. triton-windows 环境准备
参考本人之前博客 Windows 下安装 triton 教程 ,包括:
- 安装 MSVC 和 Windows SDK
- 修改环境变量
- vcredist 安装
前期环境都配置无误后,直接下载 whl 安装:
pip install https://github.com/woct0rdho/triton-windows/releases/download/v3.1.0-windows.post5/triton-3.1.0-cp310-cp310-win_amd64.whl
也可手动下载下来然后在下载路径下安装:
pip install triton-3.1.0-cp310-cp310-win_amd64.whl
验证脚本为:
import torch
import triton
import triton.language as tl
@triton.jit
def add_kernel(x_ptr, y_ptr, output_ptr, n_elements, BLOCK_SIZE: tl.constexpr):
pid = tl.program_id(axis=0)
block_start = pid * BLOCK_SIZE
offsets = block_start + tl.arange(0, BLOCK_SIZE)
mask = offsets < n_elements
x = tl.load(x_ptr + offsets, mask=mask)
y = tl.load(y_ptr + offsets, mask=mask)
output = x + y
tl.store(output_ptr + offsets, output, mask=mask)
def add(x: torch.Tensor, y: torch.Tensor):
output = torch.empty_like(x)
assert x.is_cuda and y.is_cuda and output.is_cuda
n_elements = output.numel()
grid = lambda meta: (triton.cdiv(n_elements, meta["BLOCK_SIZE"]),)
add_kernel[grid](x, y, output, n_elements, BLOCK_SIZE=1024)
return output
a = torch.rand(3, device="cuda")
b = a + a
b_compiled = add(a, a)
print(b_compiled - b)
print("If you see tensor([0., 0., 0.], device='cuda:0'), then it works")
不报错即说明配置成功。
3. 从源码编译causal-conv1d 1.4.0 版本
步骤还是参考本人原来博客 “Windows 下Mamba2 环境安装问题记录及解决方法(causal_conv1d=1.4.0)”,不过有可能会遭遇问题,需要先
conda install nvidia/label/cuda-12.4.0::cuda-cccl
如果下载缓慢,可以先把安装包下载下来,然后进行本地安装
conda install --use-local cuda-cccl-12.4.99-0.tar.bz2
接着是下载工程文件,即
git clone https://github.com/Dao-AILab/causal-conv1d.git
cd causal-conv1d
set CAUSAL_CONV1D_FORCE_BUILD=TRUE # 也可修改setup.py第37行
# 先按照博客修改源码然后再执行这最后一步
pip install .
在执行最后一步编译之前,还是需要修改,参考本人原来博客 “Windows 下Mamba2 环境安装问题记录及解决方法(causal_conv1d=1.4.0)”。
4. 从源码编译 mamba-ssm 版本
前期准备以及部分文件的修改同原来博客 “Windows 下Mamba2 环境安装问题记录及解决方法(causal_conv1d=1.4.0)”,具体来说:
1)mamba-ssm 环境准备,下载工程文件,即
git clone https://github.com/state-spaces/mamba.git
cd mamba
set MAMBA_FORCE_BUILD=TRUE # 也可修改setup.py第40行
# 先按照博客修改源码然后再执行这最后一步
pip install . --no-build-isolation
2)在执行最后一步编译之前,还是需要修改,参考本人原来博客 “Windows 下Mamba2 环境安装问题记录及解决方法(causal_conv1d=1.4.0)”
5. Mamba 环境运行验证
参考官方的 readme 文件,运行以下示例:
import torch
from mamba_ssm import Mamba
from mamba_ssm import Mamba2
batch, length, dim = 2, 64, 16
x = torch.randn(batch, length, dim).to("cuda")
model = Mamba(
# This module uses roughly 3 * expand * d_model^2 parameters
d_model=dim, # Model dimension d_model
d_state=16, # SSM state expansion factor
d_conv=4, # Local convolution width
expand=2, # Block expansion factor
).to("cuda")
y = model(x)
assert y.shape == x.shape
print('Mamba:', x.shape)
batch, length, dim = 2, 64, 256
x = torch.randn(batch, length, dim).to("cuda")
model = Mamba2(
# This module uses roughly 3 * expand * d_model^2 parameters
d_model=dim, # Model dimension d_model
d_state=64, # SSM state expansion factor, typically 64 or 128
d_conv=4, # Local convolution width
expand=2, # Block expansion factor
).to("cuda")
y = model(x)
assert y.shape == x.shape
print('Mamba2:', x.shape)
正常输出结果无报错。如下图所示,不再出现 KeyError: 'HOME' :

6. Windows 下 Vim 的安装
Vim 官方代码仓给的 causal-conv1d 源码有误,过于老旧且不兼容,causal-conv1d版本应≥1.1.0,其他部分还是参考原来的博客 Window 下 Vim 环境安装踩坑问题汇总及解决方法:
git clone https://github.com/Dao-AILab/causal-conv1d.git
cd causal-conv1d
git checkout v1.1.1 # 安装最新版的话,此步可省略
set CAUSAL_CONV1D_FORCE_BUILD=TRUE
pip install .
注意在 pip install -r vim/vim_requirements.txt 其他环境时,将 vim/vim_requirements.txt 里面的triton版本注释掉。
7. Vim 环境运行验证
运行以下示例:
# Copyright (c) 2015-present, Facebook, Inc.
# All rights reserved.
import torch
import torch.nn as nn
from functools import partial
from torch import Tensor
from typing import Optional
from timm.models.vision_transformer import VisionTransformer, _cfg
from timm.models.registry import register_model
from timm.models.layers import trunc_normal_, lecun_normal_
from timm.models.layers import DropPath, to_2tuple
from timm.models.vision_transformer import _load_weights
import math
from collections import namedtuple
from mamba_ssm.modules.mamba_simple import Mamba
from mamba_ssm.utils.generation import GenerationMixin
from mamba_ssm.utils.hf import load_config_hf, load_state_dict_hf
from rope import *
import random
try:
from mamba_ssm.ops.triton.layernorm import RMSNorm, layer_norm_fn, rms_norm_fn
except ImportError:
RMSNorm, layer_norm_fn, rms_norm_fn = None, None, None
__all__ = [
'vim_tiny_patch16_224', 'vim_small_patch16_224', 'vim_base_patch16_224',
'vim_tiny_patch16_384', 'vim_small_patch16_384', 'vim_base_patch16_384',
]
class PatchEmbed(nn.Module):
""" 2D Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, stride=16, in_chans=3, embed_dim=768, norm_layer=None,
flatten=True):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size
self.grid_size = ((img_size[0] - patch_size[0]) // stride + 1, (img_size[1] - patch_size[1]) // stride + 1)
self.num_patches = self.grid_size[0] * self.grid_size[1]
self.flatten = flatten
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=stride)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
B, C, H, W = x.shape
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x)
if self.flatten:
x = x.flatten(2).transpose(1, 2) # BCHW -> BNC
x = self.norm(x)
return x
class Block(nn.Module):
def __init__(
self, dim, mixer_cls, norm_cls=nn.LayerNorm, fused_add_norm=False, residual_in_fp32=False, drop_path=0.,
):
"""
Simple block wrapping a mixer class with LayerNorm/RMSNorm and residual connection"
This Block has a slightly different structure compared to a regular
prenorm Transformer block.
The standard block is: LN -> MHA/MLP -> Add.
[Ref: https://arxiv.org/abs/2002.04745]
Here we have: Add -> LN -> Mixer, returning both
the hidden_states (output of the mixer) and the residual.
This is purely for performance reasons, as we can fuse add and LayerNorm.
The residual needs to be provided (except for the very first block).
"""
super().__init__()
self.residual_in_fp32 = residual_in_fp32
self.fused_add_norm = fused_add_norm
self.mixer = mixer_cls(dim)
self.norm = norm_cls(dim)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
if self.fused_add_norm:
assert RMSNorm is not None, "RMSNorm import fails"
assert isinstance(
self.norm, (nn.LayerNorm, RMSNorm)
), "Only LayerNorm and RMSNorm are supported for fused_add_norm"
def forward(
self, hidden_states: Tensor, residual: Optional[Tensor] = None, inference_params=None
):
r"""Pass the input through the encoder layer.
Args:
hidden_states: the sequence to the encoder layer (required).
residual: hidden_states = Mixer(LN(residual))
"""
if not self.fused_add_norm:
if residual is None:
residual = hidden_states
else:
residual = residual + self.drop_path(hidden_states)
hidden_states = self.norm(residual.to(dtype=self.norm.weight.dtype))
if self.residual_in_fp32:
residual = residual.to(torch.float32)
else:
fused_add_norm_fn = rms_norm_fn if isinstance(self.norm, RMSNorm) else layer_norm_fn
if residual is None:
hidden_states, residual = fused_add_norm_fn(
hidden_states,
self.norm.weight,
self.norm.bias,
residual=residual,
prenorm=True,
residual_in_fp32=self.residual_in_fp32,
eps=self.norm.eps,
)
else:
hidden_states, residual = fused_add_norm_fn(
self.drop_path(hidden_states),
self.norm.weight,
self.norm.bias,
residual=residual,
prenorm=True,
residual_in_fp32=self.residual_in_fp32,
eps=self.norm.eps,
)
hidden_states = self.mixer(hidden_states, inference_params=inference_params)
return hidden_states, residual
def allocate_inference_cache(self, batch_size, max_seqlen, dtype=None, **kwargs):
return self.mixer.allocate_inference_cache(batch_size, max_seqlen, dtype=dtype, **kwargs)
def create_block(
d_model,
ssm_cfg=None,
norm_epsilon=1e-5,
drop_path=0.,
rms_norm=False,
residual_in_fp32=False,
fused_add_norm=False,
layer_idx=None,
device=None,
dtype=None,
if_bimamba=False,
bimamba_type="none",
if_divide_out=False,
init_layer_scale=None,
):
if if_bimamba:
bimamba_type = "v1"
if ssm_cfg is None:
ssm_cfg = {}
factory_kwargs = {"device": device, "dtype": dtype}
mixer_cls = partial(Mamba, layer_idx=layer_idx, bimamba_type=bimamba_type, if_divide_out=if_divide_out,
init_layer_scale=init_layer_scale, **ssm_cfg, **factory_kwargs)
norm_cls = partial(
nn.LayerNorm if not rms_norm else RMSNorm, eps=norm_epsilon, **factory_kwargs
)
block = Block(
d_model,
mixer_cls,
norm_cls=norm_cls,
drop_path=drop_path,
fused_add_norm=fused_add_norm,
residual_in_fp32=residual_in_fp32,
)
block.layer_idx = layer_idx
return block
# https://github.com/huggingface/transformers/blob/c28d04e9e252a1a099944e325685f14d242ecdcd/src/transformers/models/gpt2/modeling_gpt2.py#L454
def _init_weights(
module,
n_layer,
initializer_range=0.02, # Now only used for embedding layer.
rescale_prenorm_residual=True,
n_residuals_per_layer=1, # Change to 2 if we have MLP
):
if isinstance(module, nn.Linear):
if module.bias is not None:
if not getattr(module.bias, "_no_reinit", False):
nn.init.zeros_(module.bias)
elif isinstance(module, nn.Embedding):
nn.init.normal_(module.weight, std=initializer_range)
if rescale_prenorm_residual:
# Reinitialize selected weights subject to the OpenAI GPT-2 Paper Scheme:
# > A modified initialization which accounts for the accumulation on the residual path with model depth. Scale
# > the weights of residual layers at initialization by a factor of 1/√N where N is the # of residual layers.
# > -- GPT-2 :: https://openai.com/blog/better-language-models/
#
# Reference (Megatron-LM): https://github.com/NVIDIA/Megatron-LM/blob/main/megatron/model/gpt_model.py
for name, p in module.named_parameters():
if name in ["out_proj.weight", "fc2.weight"]:
# Special Scaled Initialization --> There are 2 Layer Norms per Transformer Block
# Following Pytorch init, except scale by 1/sqrt(2 * n_layer)
# We need to reinit p since this code could be called multiple times
# Having just p *= scale would repeatedly scale it down
nn.init.kaiming_uniform_(p, a=math.sqrt(5))
with torch.no_grad():
p /= math.sqrt(n_residuals_per_layer * n_layer)
def segm_init_weights(m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=0.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Conv2d):
# NOTE conv was left to pytorch default in my original init
lecun_normal_(m.weight)
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, (nn.LayerNorm, nn.GroupNorm, nn.BatchNorm2d)):
nn.init.zeros_(m.bias)
nn.init.ones_(m.weight)
class VisionMamba(nn.Module):
def __init__(self,
img_size=224,
patch_size=16,
stride=16,
depth=24,
embed_dim=192,
channels=3,
num_classes=1000,
ssm_cfg=None,
drop_rate=0.,
drop_path_rate=0.1,
norm_epsilon: float = 1e-5,
rms_norm: bool = False,
initializer_cfg=None,
fused_add_norm=False,
residual_in_fp32=False,
device=None,
dtype=None,
ft_seq_len=None,
pt_hw_seq_len=14,
if_bidirectional=False,
final_pool_type='none',
if_abs_pos_embed=False,
if_rope=False,
if_rope_residual=False,
flip_img_sequences_ratio=-1.,
if_bimamba=False,
bimamba_type="none",
if_cls_token=False,
if_divide_out=False,
init_layer_scale=None,
use_double_cls_token=False,
use_middle_cls_token=False,
**kwargs):
factory_kwargs = {"device": device, "dtype": dtype}
# add factory_kwargs into kwargs
kwargs.update(factory_kwargs)
super().__init__()
self.residual_in_fp32 = residual_in_fp32
self.fused_add_norm = fused_add_norm
self.if_bidirectional = if_bidirectional
self.final_pool_type = final_pool_type
self.if_abs_pos_embed = if_abs_pos_embed
self.if_rope = if_rope
self.if_rope_residual = if_rope_residual
self.flip_img_sequences_ratio = flip_img_sequences_ratio
self.if_cls_token = if_cls_token
self.use_double_cls_token = use_double_cls_token
self.use_middle_cls_token = use_middle_cls_token
self.num_tokens = 1 if if_cls_token else 0
# pretrain parameters
self.num_classes = num_classes
self.d_model = self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, stride=stride, in_chans=channels, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
if if_cls_token:
if use_double_cls_token:
self.cls_token_head = nn.Parameter(torch.zeros(1, 1, self.embed_dim))
self.cls_token_tail = nn.Parameter(torch.zeros(1, 1, self.embed_dim))
self.num_tokens = 2
else:
self.cls_token = nn.Parameter(torch.zeros(1, 1, self.embed_dim))
# self.num_tokens = 1
if if_abs_pos_embed:
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, self.embed_dim))
self.pos_drop = nn.Dropout(p=drop_rate)
if if_rope:
half_head_dim = embed_dim // 2
hw_seq_len = img_size // patch_size
self.rope = VisionRotaryEmbeddingFast(
dim=half_head_dim,
pt_seq_len=pt_hw_seq_len,
ft_seq_len=hw_seq_len
)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
# TODO: release this comment
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
# import ipdb;ipdb.set_trace()
inter_dpr = [0.0] + dpr
self.drop_path = DropPath(drop_path_rate) if drop_path_rate > 0. else nn.Identity()
# transformer blocks
self.layers = nn.ModuleList(
[
create_block(
embed_dim,
ssm_cfg=ssm_cfg,
norm_epsilon=norm_epsilon,
rms_norm=rms_norm,
residual_in_fp32=residual_in_fp32,
fused_add_norm=fused_add_norm,
layer_idx=i,
if_bimamba=if_bimamba,
bimamba_type=bimamba_type,
drop_path=inter_dpr[i],
if_divide_out=if_divide_out,
init_layer_scale=init_layer_scale,
**factory_kwargs,
)
for i in range(depth)
]
)
# output head
self.norm_f = (nn.LayerNorm if not rms_norm else RMSNorm)(
embed_dim, eps=norm_epsilon, **factory_kwargs
)
# self.pre_logits = nn.Identity()
# original init
self.patch_embed.apply(segm_init_weights)
self.head.apply(segm_init_weights)
if if_abs_pos_embed:
trunc_normal_(self.pos_embed, std=.02)
if if_cls_token:
if use_double_cls_token:
trunc_normal_(self.cls_token_head, std=.02)
trunc_normal_(self.cls_token_tail, std=.02)
else:
trunc_normal_(self.cls_token, std=.02)
# mamba init
self.apply(
partial(
_init_weights,
n_layer=depth,
**(initializer_cfg if initializer_cfg is not None else {}),
)
)
def allocate_inference_cache(self, batch_size, max_seqlen, dtype=None, **kwargs):
return {
i: layer.allocate_inference_cache(batch_size, max_seqlen, dtype=dtype, **kwargs)
for i, layer in enumerate(self.layers)
}
@torch.jit.ignore
def no_weight_decay(self):
return {"pos_embed", "cls_token", "dist_token", "cls_token_head", "cls_token_tail"}
@torch.jit.ignore()
def load_pretrained(self, checkpoint_path, prefix=""):
_load_weights(self, checkpoint_path, prefix)
def forward_features(self, x, inference_params=None, if_random_cls_token_position=False,
if_random_token_rank=False):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
# with slight modifications to add the dist_token
x = self.patch_embed(x)
B, M, _ = x.shape
if self.if_cls_token:
if self.use_double_cls_token:
cls_token_head = self.cls_token_head.expand(B, -1, -1)
cls_token_tail = self.cls_token_tail.expand(B, -1, -1)
token_position = [0, M + 1]
x = torch.cat((cls_token_head, x, cls_token_tail), dim=1)
M = x.shape[1]
else:
if self.use_middle_cls_token:
cls_token = self.cls_token.expand(B, -1, -1)
token_position = M // 2
# add cls token in the middle
x = torch.cat((x[:, :token_position, :], cls_token, x[:, token_position:, :]), dim=1)
elif if_random_cls_token_position:
cls_token = self.cls_token.expand(B, -1, -1)
token_position = random.randint(0, M)
x = torch.cat((x[:, :token_position, :], cls_token, x[:, token_position:, :]), dim=1)
print("token_position: ", token_position)
else:
cls_token = self.cls_token.expand(B, -1, -1) # stole cls_tokens impl from Phil Wang, thanks
token_position = 0
x = torch.cat((cls_token, x), dim=1)
M = x.shape[1]
if self.if_abs_pos_embed:
# if new_grid_size[0] == self.patch_embed.grid_size[0] and new_grid_size[1] == self.patch_embed.grid_size[1]:
# x = x + self.pos_embed
# else:
# pos_embed = interpolate_pos_embed_online(
# self.pos_embed, self.patch_embed.grid_size, new_grid_size,0
# )
x = x + self.pos_embed
x = self.pos_drop(x)
if if_random_token_rank:
# 生成随机 shuffle 索引
shuffle_indices = torch.randperm(M)
if isinstance(token_position, list):
print("original value: ", x[0, token_position[0], 0], x[0, token_position[1], 0])
else:
print("original value: ", x[0, token_position, 0])
print("original token_position: ", token_position)
# 执行 shuffle
x = x[:, shuffle_indices, :]
if isinstance(token_position, list):
# 找到 cls token 在 shuffle 之后的新位置
new_token_position = [torch.where(shuffle_indices == token_position[i])[0].item() for i in
range(len(token_position))]
token_position = new_token_position
else:
# 找到 cls token 在 shuffle 之后的新位置
token_position = torch.where(shuffle_indices == token_position)[0].item()
if isinstance(token_position, list):
print("new value: ", x[0, token_position[0], 0], x[0, token_position[1], 0])
else:
print("new value: ", x[0, token_position, 0])
print("new token_position: ", token_position)
if_flip_img_sequences = False
if self.flip_img_sequences_ratio > 0 and (self.flip_img_sequences_ratio - random.random()) > 1e-5:
x = x.flip([1])
if_flip_img_sequences = True
# mamba impl
residual = None
hidden_states = x
if not self.if_bidirectional:
for layer in self.layers:
if if_flip_img_sequences and self.if_rope:
hidden_states = hidden_states.flip([1])
if residual is not None:
residual = residual.flip([1])
# rope about
if self.if_rope:
hidden_states = self.rope(hidden_states)
if residual is not None and self.if_rope_residual:
residual = self.rope(residual)
if if_flip_img_sequences and self.if_rope:
hidden_states = hidden_states.flip([1])
if residual is not None:
residual = residual.flip([1])
hidden_states, residual = layer(
hidden_states, residual, inference_params=inference_params
)
else:
# get two layers in a single for-loop
for i in range(len(self.layers) // 2):
if self.if_rope:
hidden_states = self.rope(hidden_states)
if residual is not None and self.if_rope_residual:
residual = self.rope(residual)
hidden_states_f, residual_f = self.layers[i * 2](
hidden_states, residual, inference_params=inference_params
)
hidden_states_b, residual_b = self.layers[i * 2 + 1](
hidden_states.flip([1]), None if residual == None else residual.flip([1]),
inference_params=inference_params
)
hidden_states = hidden_states_f + hidden_states_b.flip([1])
residual = residual_f + residual_b.flip([1])
if not self.fused_add_norm:
if residual is None:
residual = hidden_states
else:
residual = residual + self.drop_path(hidden_states)
hidden_states = self.norm_f(residual.to(dtype=self.norm_f.weight.dtype))
else:
# Set prenorm=False here since we don't need the residual
fused_add_norm_fn = rms_norm_fn if isinstance(self.norm_f, RMSNorm) else layer_norm_fn
hidden_states = fused_add_norm_fn(
self.drop_path(hidden_states),
self.norm_f.weight,
self.norm_f.bias,
eps=self.norm_f.eps,
residual=residual,
prenorm=False,
residual_in_fp32=self.residual_in_fp32,
)
# return only cls token if it exists
if self.if_cls_token:
if self.use_double_cls_token:
return (hidden_states[:, token_position[0], :] + hidden_states[:, token_position[1], :]) / 2
else:
if self.use_middle_cls_token:
return hidden_states[:, token_position, :]
elif if_random_cls_token_position:
return hidden_states[:, token_position, :]
else:
return hidden_states[:, token_position, :]
if self.final_pool_type == 'none':
return hidden_states[:, -1, :]
elif self.final_pool_type == 'mean':
return hidden_states.mean(dim=1)
elif self.final_pool_type == 'max':
return hidden_states
elif self.final_pool_type == 'all':
return hidden_states
else:
raise NotImplementedError
def forward(self, x, return_features=False, inference_params=None, if_random_cls_token_position=False,
if_random_token_rank=False):
x = self.forward_features(x, inference_params, if_random_cls_token_position=if_random_cls_token_position,
if_random_token_rank=if_random_token_rank)
# if return_features:
# return x
# x = self.head(x)
# if self.final_pool_type == 'max':
# x = x.max(dim=1)[0]
return x
@register_model
def vim_tiny_patch16_224_bimambav2_final_pool_mean_abs_pos_embed_with_midclstok_div2(pretrained=False, **kwargs):
model = VisionMamba(
patch_size=16, embed_dim=192, depth=24, rms_norm=True, residual_in_fp32=True, fused_add_norm=True,
final_pool_type='mean', if_abs_pos_embed=True, if_rope=False, if_rope_residual=False, bimamba_type="v2",
if_cls_token=True, if_divide_out=True, use_middle_cls_token=True, **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="to.do",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def vim_tiny_patch16_stride8_224_bimambav2_final_pool_mean_abs_pos_embed_with_midclstok_div2(pretrained=False,
**kwargs):
model = VisionMamba(
patch_size=16, stride=8, embed_dim=192, depth=24, rms_norm=True, residual_in_fp32=True, fused_add_norm=True,
final_pool_type='mean', if_abs_pos_embed=True, if_rope=False, if_rope_residual=False, bimamba_type="v2",
if_cls_token=True, if_divide_out=True, use_middle_cls_token=True, **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="to.do",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def vim_small_patch16_224_bimambav2_final_pool_mean_abs_pos_embed_with_midclstok_div2(pretrained=False, **kwargs):
model = VisionMamba(
patch_size=16, embed_dim=384, depth=24, rms_norm=True, residual_in_fp32=True, fused_add_norm=True,
final_pool_type='mean', if_abs_pos_embed=True, if_rope=False, if_rope_residual=False, bimamba_type="v2",
if_cls_token=True, if_divide_out=True, use_middle_cls_token=True, **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="to.do",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def vim_small_patch16_stride8_224_bimambav2_final_pool_mean_abs_pos_embed_with_midclstok_div2(pretrained=False,
**kwargs):
model = VisionMamba(
patch_size=16, stride=8, embed_dim=384, depth=24, rms_norm=True, residual_in_fp32=True, fused_add_norm=True,
final_pool_type='mean', if_abs_pos_embed=True, if_rope=False, if_rope_residual=False, bimamba_type="v2",
if_cls_token=True, if_divide_out=True, use_middle_cls_token=True, **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="to.do",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint["model"])
return model
if __name__ == '__main__':
# cuda or cpu
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
# 实例化模型得到分类结果
inputs = torch.randn(1, 3, 224, 224).to(device)
model = vim_small_patch16_stride8_224_bimambav2_final_pool_mean_abs_pos_embed_with_midclstok_div2(
pretrained=False).to(device)
# print(model)
outputs = model(inputs)
print(outputs.shape)
# 实例化mamba模块,输入输出特征维度不变 B C H W
x = torch.rand(10, 16, 64, 128).to(device)
B, C, H, W = x.shape
print("输入特征维度:", x.shape)
x = x.view(B, C, H * W).permute(0, 2, 1)
print("维度变换:", x.shape)
mamba = create_block(d_model=C).to(device)
# mamba模型代码中返回的是一个元组:hidden_states, residual
hidden_states, residual = mamba(x)
x = hidden_states.permute(0, 2, 1).view(B, C, H, W)
print("输出特征维度:", x.shape)
正常输出结果无报错。如下图所示,不再出现 KeyError: 'HOME' 或者 RuntimeError: failed to find C compiler:

8. Windows 下 Vmamba 的安装
依旧参考原来的博客:Windows 下 VMamba 安装教程(无需更改base环境中的cuda版本且可加速) 。
9. Vmamba 环境运行验证
运行以下示例:
import torch
import triton
import triton.language as tl
@triton.jit
def add_kernel(x_ptr, y_ptr, output_ptr, n_elements, BLOCK_SIZE: tl.constexpr):
pid = tl.program_id(axis=0)
block_start = pid * BLOCK_SIZE
offsets = block_start + tl.arange(0, BLOCK_SIZE)
mask = offsets < n_elements
x = tl.load(x_ptr + offsets, mask=mask)
y = tl.load(y_ptr + offsets, mask=mask)
output = x + y
tl.store(output_ptr + offsets, output, mask=mask)
def add(x: torch.Tensor, y: torch.Tensor):
output = torch.empty_like(x)
assert x.is_cuda and y.is_cuda and output.is_cuda
n_elements = output.numel()
grid = lambda meta: (triton.cdiv(n_elements, meta["BLOCK_SIZE"]),)
add_kernel[grid](x, y, output, n_elements, BLOCK_SIZE=1024)
return output
a = torch.rand(3, device="cuda")
b = a + a
b_compiled = add(a, a)
print(b_compiled - b)
print("If you see tensor([0., 0., 0.], device='cuda:0'), then it works")
正常输出结果无报错。如下图所示,不再出现 KeyError: 'HOME' 或者 RuntimeError: failed to find C compiler:

出现的问题
1. 出现 fatal error C1083: 无法打开包括文件: “nv/target”'
具体来说出现以下报错
D:\software\Anaconda\envs\mamba\include\cuda_fp16.h(4100): fatal error C1083: 无法打开包括文件: “nv/target”: No such file or directory
即出现
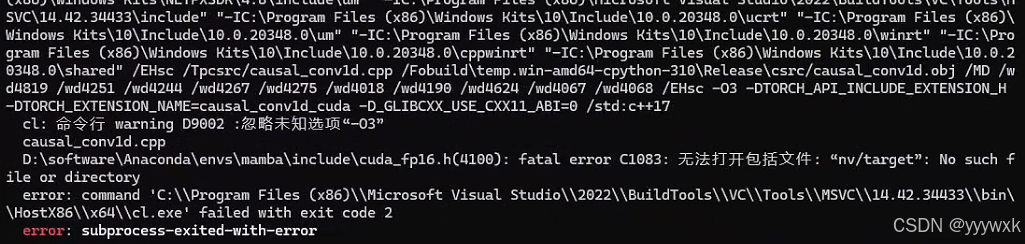
说明其中环境中缺少 CUDA C++ 核心计算库 (CUDA C++ Core Libraries, CCCL),解决方法即为:
conda install nvidia/label/cuda-12.4.0::cuda-cccl